TCW Beratungsleistung Data Science
Anwendungsbereiche und Use Cases
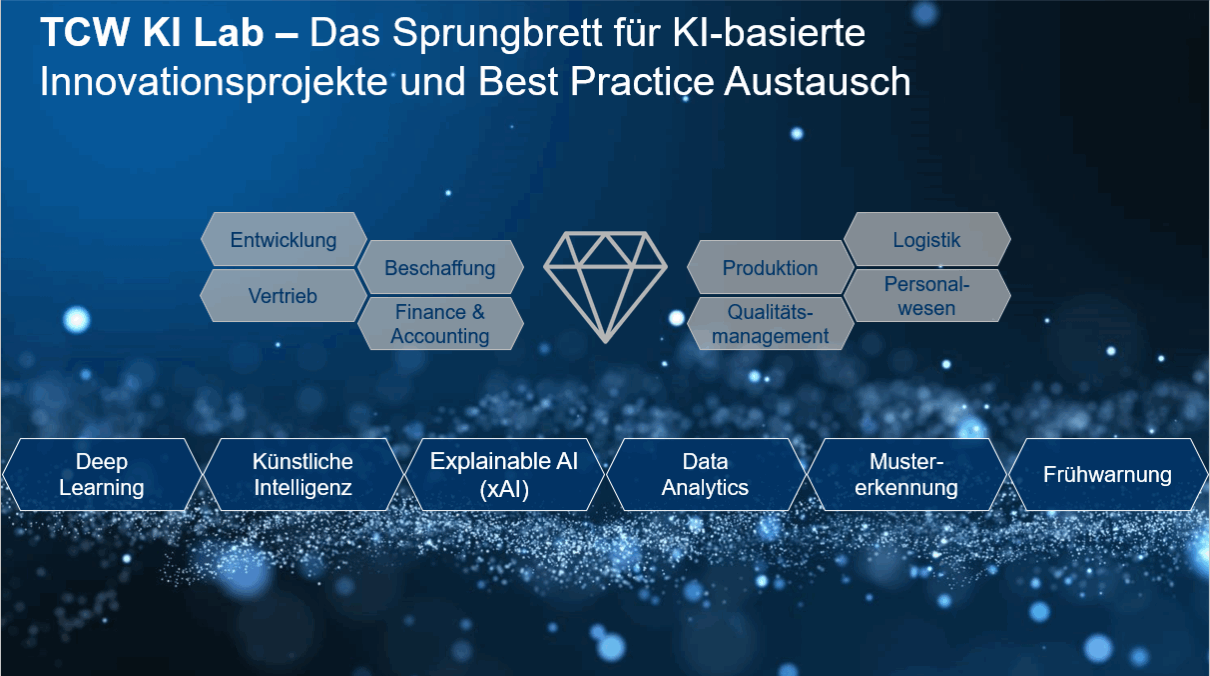
Endlich den Datenschatz heben mit dem TCW KI Lab
Das KI Lab eröffnet Unternehmen die Nutzung von Potentialen durch Technologien der Datenverarbeitung und bietet... [mehr]

Data Science und KI für Frühwarnsysteme in der Beschaffung
Besser vorbereitet auf Bauteilknappheit und Supply Chain Risiken durch Data Science und Künstliche Intelligenz. So funktioniert der TCW Ansatz ... [mehr]

Erfolgreiche Implementierung von Data Science im Einkauf
Effizienzsteigerung und Kostenreduktion durch den Einsatz von Data Science im operativen Einkauf bei einem Anlagenhersteller. ... [mehr]
Umsatzsteigerung durch die optimierte Nutzung von Sales-und Plattformdaten
Die konzernweite Integration, Auswertung und Nutzung von Vertriebsdaten aus verschiedenen Business Units bietet Unternehmen ... [mehr]

Anlagenüberwachung und Predictive Maintenance durch Machine Learning
Historische Betriebs-, Ausfall- und Sensordaten von Maschinen und Großanlagen lassen sich mit Machine Learning in Echtzeit ... [mehr]

Qualitätsoptimierung im Shopfloor durch den Einsatz von Big Data Analytics
In vielen Unternehmen weisen Produktionsbereiche unterschiedliche Qualitätsniveaus auf. Über algorithmengestützte Big Data Analysen ... [mehr]
Smartes Bestandsmanagement mit Big Data und Künstlicher Intelligenz
Durch die Optimierung des Bestandsmanagements können Potenziale in zahlreichen Unternehmensbereichen realisiert werden ... [mehr]

Remote Business Intelligence als Reaktion auf die Corona Krise
Remote Business Intelligence bedeutet Hilfestellung bei strategischen Entscheidungen durch toolbasierte Datenanalysen ... [mehr]
Data Science bedeutet das Lernen aus Daten zu systematisieren
Die große Menge und Vielfalt vorhandener und neuer Daten, die heute in der Welt generiert werden, ist beispiellos. Mit den richtigen Tools können darin Muster erkannt werden, welche zu einer Optimierung von Prozessen und der Ressourcenallokation genutzt werden können.
Wie unterstützt TCW bei der Einführung von Data Science?
Wir helfen unseren Kunden wertvolle und aussagekräftige Erkenntnisse aus ihren Daten zu identifizieren und diese in Wettbewerbsvorteile umzuwandeln. TCW unterstützt sie bei der Identifikation von sinnvollen Anwendungsfeldern, bei der Datenaufbereitung und -zusammenführung bis hin zur Einführung und organisatorischen Verankerung von Data Science im Unternehmen. Wir helfen Ihnen dabei mit der Hilfe von Daten faktenbasierte Entscheidungen zu treffen und somit zu einem analytisch orientierten Unternehmen zu werden.

Wir begleiten Kunden von der Entwicklung von Use Cases über die Entwicklung von Prototypen bis hin zum unternehmensweiten Rollout.
Wir verknüpfen
- Erfahrungswissen aus verschiedenen Branchen,
- eine Benchmark-Datenbank mit Referenzfallbeispielen von erfolgreich umgesetzten Anwendungen,
- pragmatische Analytics-Tools, die auch verteilte und unvollständige Datenstämme nutzbar machen sowie
- State-of-the-Art Analysesoftware und erprobte Algorithmen in einem ganzheitlichen Konzept.
Hierbei agieren wir als technologieunabhängiger Berater und Umsetzungsunterstützer. Wir sind überzeugt, dass ein werthaltiger Beratungsansatz erst dann entsteht, wenn die Datenanalyse mit menschlichem Erfahrungswissen kombiniert wird, denn dann können daraus die richtigen Schlussfolgerungen gezogen werden.
Wie sieht das TCW Vorgehensmodell aus?
Das TCW wendet ein vierstufiges Verfahren an, dass messbare Ergebnisse gewährleistet:
1. Use Case Hypothese- Analyse und Benchmarking der zu betrachtenden Unternehmensfunktion,
- Identifikation der Pain-Points und der Werthebel in der Wertschöpfungskette,
- Identifikation von möglichen Use-Cases,
- Ableitung von Ursachen-/Wirkungsanalyse zur Ableitung von Data Science Hypothesen
- Analyse der Datenqualität und Datenverfügbarkeit
- Konsolidierung der Daten aus verschiedensten Datenquellen (keine perfekte Datenqualität notwendig) sowie
- Daten-Mapping und Datenbereinigung
- Bewertung des Mehrwerts verschiedener Data Science Modelle für das Unternehmen
- Abschätzung der Investitionsaufwände und der Umsetzungsdauer
- Kosten-/Nutzenanalyse zur Bewertung von verschiedenen Anwendungsfeldern
- Mustererkennung im Data Lake zur Identifikation von Mustern und Auffälligkeiten
- Testen von verschiedenen Algorithmen und Algorithmenauswahl
- Entwurf eines funktionsfähigen Data Science Modells und Anwendungs-Tools
- Einführung des Prototyps im entsprechenden Unternehmensbereich und Anwendung unter echten Bedingungen
- Verfeinerung des Tools und Weiterentwicklung des Modells anhand der Lessons Learned
- Einführung und Eingliederung des Modells in die Unternehmensprozesse
- Umsetzungsbegleitung und Schulung der Mitarbeiter
- Transfer des Know-Hows auf weitere Anwendungsfelder
Welche Kompetenz ist das Alleinstellungsmerkmal des TCW?
Unsere Teams bestehen nicht nur aus Mathematikern oder IT-Experten. Unsere Data Scientists agieren an der Schnittstelle zwischen Data Analytics und Betriebswirtschaft, das heißt wir agieren als intelligente Übersetzer und unterstützen die Unternehmen bei der Entwicklung von Konzepten, welche sich durch realisierbare Potenziale auszeichnen.
Die Data Scientists bringen Erfahrungswissen und analytisches Know-How mit, um schnell zu identifizieren, welche Besonderheiten im Unternehmensbereich zu berücksichtigen sind und vor allem – wo die Werthebel liegen! Das heißt beispielsweise zu wissen, wie der Vertriebsprozess funktioniert. Was sind die Erfolgsfaktoren in der Logistik? Welche Parameter kommen überhaupt in Frage, wenn ich eine statistische Untersuchung der Qualität im Produktionsnetz durchführen will? Die Paarung aus menschlichem Erfahrungswissen und algorithmischer Analyse-Kraft ist also die Grundvoraussetzung für die Generierung von neuen Erkenntnissen.
Unsere interdisziplinären Teams
- bestehend auf Wirtschaftswissenschaftlern,
- Data Scientists und
- Ingenieuren
verknüpfen technisches Verständnis, Branchen- und Prozesserfahrung und analytische Kompetenzen im Bereich Big Data Analytics.

Wir greifen auf ein breites Angebot an erprobten Algorithmen und Software-Tools aus den Bereichen mathematischer Optimierung, statistischer Verfahren, nicht linearer Modelle wie Entscheidungsbäume, bis hin zu unserem Deep Learning (tiefe neuronale Netze) zurück. Das TCW Konzept ermöglicht es Unternehmen, echten Mehrwert aus Daten zu generieren und Möglichkeiten zur Umsatzsteigerung und zur Kostenreduzierung zu identifizieren. Wir bauen dabei auf Erfahrungen aus erfolgreichen Referenzprojekten.
Weitere Use Cases im Bereich Data Science
Mit Advanced Analytics lassen sich betriebswirtschaftliche Probleme aufdecken, die im Dickicht der Massendaten verborgen sind, aber mit den Instrumenten der statistischen Datenanalyse ans Licht gebracht werden können. Anwenden lässt sich dieser Ansatz in allen Bereichen der Wertschöpfungskette. Wir haben an dieser Stelle einige sehr prominente Applikationen dargestellt:
- Effizienzsteigerung im operativen Einkauf
Big-Data Analysen erlauben es, Zusammenhänge zwischen Einkaufsentscheidungen (z.B. BANF-Freigaben) und den Merkmalskombinationen der BANF herzustellen. Durch eine Clusterung von BANFen gemäß den Kriterien, die in der Vergangenheit zu einer Freigabe geführt haben, kann die BANF ohne manuelle Prüfung freigegeben (oder eine andere Aktion ausgelöst) werden, wenn sie in die entsprechende Kategorie fällt. - Pricing Modelle für hybride Leistungsbündel
Ziel ist es, markt- und regionenspezifische Pricing-Modelle zu entwickeln, die eine maximale Marktabschöpfung ermöglichen. Durch eine Clusterung der regionalen Kundenbedarfe und der Erkennung von Mustern können hybride Leistungsbündel angeboten werden und es kann eine optimale Preisstrategie entwickelt werden. Ziel ist es, kaufentscheidende Merkmale in der Pricing-Strategie optimal zu berücksichtigen. - Werksübergreifende Kapazitätssimulation
Die werksübergreifende Simulation von verfügbaren Kapazitäten unter Berücksichtigung der technologischen Kompetenzen ist in Unternehmen aufgrund der komplexen Zusammenhänge häufig nur schwer möglich. Big Data Analysen erlauben es, die Vielzahl an kapazitätsrelevanten Daten in den einzelnen Werken zu standardisieren und zu vergleichen. Dadurch lässt sich eine prognosegestützte, optimiere Ressourcenplanung und ein Effizienzgewinn erreichen. - Optimierung der Produktivität in der Produktion durch Ursache-/Wirkungsanalysen
Über Regressions-Big-Data-Analysen kann festgestellt werden, welche Ursachen eine hohe Produktivität (z.B. First-Pass-Yield, Durchlaufzeiten etc.) begünstigen. Ziel ist es, in einem Produktionsnetz erfolgreiche und weniger erfolgreiche Standorte zu analysieren und Muster zu erkennen, durch welche die Produktivität gesteigert werden kann. - Beschleunigung der Produktentwicklungszeit in der chemischen Industrie
Neue Produkte werden in der chemischen Industrie in Labortests entwickelt. Viele Einflussfaktoren wie etwa Rezepturen oder Verfahrensparameter haben einen Einfluss auf die Produktgüte. Labortests können deutlich effizienter sein, wenn über Big Data die Muster zwischen Einflussfaktoren (Rezepturen, Verfahren etc.) und Prozessergebnissen hergestellt werden können. Dies bedeutet eine deutliche Beschleunigung gegenüber dem Trial-and-Error-Verfahren. - Auspreisung komplexer Produktportfolios
Automatisierte Bepreisung der Varianten mit präziserer Berücksichtigung entsprechend der Spezifika und optimaler Abschöpfung des Marktes. - Optimierung der Materialanstellung
Festlegung der Verpackungsgrößen unter Berücksichtigung aller Einflussfaktoren aus Sicht von Montage und Logistik. Auslastungsoptimierung in Vormontagebereichen unter Berücksichtigung sämtlicher Einflussgrößen.